---
title: "NBA MVP Comparisons - Part 2"
date: "2019-02-27"
author: "Kivan Polimis"
description: "Using machine learning regression models to identify controversial NBA MVP awards and who was robbed."
categories: [sports-analytics, python]
image: "./age_vote_share_bivariate.png"
draft: false
---
<!-- migrated from pelican: nba_mvp_comparisons-part_2.md -->
<script type="text/x-mathjax-config">
MathJax.Hub.Config({
"HTML-CSS": {
styles: {
".MathJax .mo, .MathJax .mi": {color: "black ! important"}}
},
tex2jax: {inlineMath: [['$','$'], ['\\\\(','\\\\)']],processEscapes: true}
});
</script>
<script type="text/javascript" src="http://cdn.mathjax.org/mathjax/latest/MathJax.js?config=TeX-AMS_HTML"></script>
</head>
NBA MVP Comparisons - Part 2
============================
Part 2
------
- 27<sup>th</sup> February 2019
In the previous post, [Part
1](http://www.kivanpolimis.com/nba-mvp-comparisons-part-1.html) of the
NBA MVP Comparison series, we gathered the relevant NBA MVP finalist
data from
[basketball-reference.com](https://www.basketball-reference.com/) and
processed it.
Before going further, it is important to note that all analysis in Part
2 deals with MVP finalists from 1983 to the present (2018). This
decision was made to separate the pre-3 point era from the post-3 point
era which analytically and stylistically have different types of
players.
Our goal with this blog post is to understand which MVP finalist, but
non-MVP winner was most deserving of the award. To do this, we will
predict the continuous dependent variable, vote share (ranging from 0 to
1), of a MVP finalist with a vector (list) of the following predictors
(independent variables) from the processed MVP finalist data: age,
games\_played, avg\_minutes, avg\_points, avg\_rebounds, avg\_assists,
avg\_steals, avg\_blocks, field\_goal\_pct, three\_pt\_pct,
free\_throw\_pct, win\_shares, win\_shares\_per\_48.
The specific questions that will allow us to assess which finalist was
most deserving of a MVP award are:
1. Which MVP winner(s) outperformed their predicted vote share?
2. Which MVP winner(s) should have finished second to another finalist
in predicted vote share?
In this post, we will:
1. Compare machine learning (ML) models for selecting the MVP award
2. Identify the finalists deserving of a MVP award
While the language of statistical models deals more with over- and
under-performance, I will interchange these terms with more colloquial
language such as robbed/robbery.
Outline
-------
1. Compare Machine Learning Regression Models
2. Determine Controversial MVPs
3. Choose New MVPs
Models Overview
---------------
- Which model did well?
- To predict MVP awards and vote share, I used machine learning (ML)
regression models
- [Machine learning](https://www.coursera.org/learn/machine-learning)
refers to algorithms and models that perform predictions with
advanced pattern recognition/correlations and are devoid of explicit
human programming
- ML models were compared with the metric Root Mean Square Error
(RMSE)
### ML Regression Models
- [Random Forest
Regressor](https://en.wikipedia.org/wiki/Random_forest)
- Ensemble learning method that constructs decision trees and
creates a mean prediction of the individual trees
- [Latent Discriminant
Analysis](https://en.wikipedia.org/wiki/Linear_discriminant_analysis)
- Uses a linear combination of features to separate two or more
classes
- [Gradient Boost](https://en.wikipedia.org/wiki/Gradient_boosting)
- Uses "weak learners", predicts loosely correlated with outcome
variable, in an ensemble method to produced boosted "strong
learners" with optimization
- [XGBoost](https://www.kdnuggets.com/2017/10/xgboost-top-machine-learning-method-kaggle-explained.html)
- Gradient boosting method "robust enough to support fine tuning
and addition of regularization parameters"
Compare ML Regression Models
----------------------------
- To prepare the data for the ML models:
- I split the MVP data into training (80%) and test datasets (20%)
- The models are trained (learn the patterns) on the training set
and then compared on how well they predict the MVPs in the test
set
- Why Root Mean Square Error
[(RMSE)](https://www.statisticshowto.datasciencecentral.com/rmse/)?
$$ RMSE = \sqrt{\frac{1}{n}\sum_{i=1}^{n}(Actual_{i} - Predicted_{i})^2} $$
- RMSE is the square root of the average of squared differences
between predicted values and actual observation. The RMSE ranges
from 0 to ∞ and the direction (positive/negative) of the residual
(Prediction - Actual) is inconsequential because the residual is
squared. Lower RMSE correspond with better performing models.
- RMSE equation as a function in R:
<!-- -->
RMSE = function(actual, predicted) {
RMSE = sqrt(sum(mean(actual-predicted)^2))
return(RMSE)
}
<table style="width:53%;">
<caption>RMSE Table</caption>
<colgroup>
<col width="43%" />
<col width="9%" />
</colgroup>
<thead>
<tr class="header">
<th align="left">Machine Learning Model</th>
<th align="center">RMSE</th>
</tr>
</thead>
<tbody>
<tr class="odd">
<td align="left">Latent Discriminant Analysis</td>
<td align="center">0.002</td>
</tr>
<tr class="even">
<td align="left">XGBoost - Linear</td>
<td align="center">0.004</td>
</tr>
<tr class="odd">
<td align="left">Random Forest Classifier</td>
<td align="center">0.005</td>
</tr>
<tr class="even">
<td align="left">Gradient Boost</td>
<td align="center">0.011</td>
</tr>
<tr class="odd">
<td align="left">XGBoost - Tree</td>
<td align="center">0.012</td>
</tr>
</tbody>
</table>
- The Latent Discriminant Analysis (LDA) was the best performing
model
- Henceforth, "the model" will refer to the LDA model
### Latent Discriminant Analysis (LDA)
Because our predicted variable, vote share, is continuous we need a rule
to predict the binary (winner/loser(s)) MVP award. The rule we will use
is the player with the maximum predicted vote share (LDA Prediction) for
a given year will be awarded the MVP. This rule will need additional
complexity to handle potential ties. The order of tiebreakers for
playoff seeding is near the bottom of [this
article](https://www.nbcsports.com/washington/wizards/how-are-nba-playoff-seeding-tiebreakers-determined-wizards-fans-may-want-brush-them).
Perhaps we could adopt similar rules for vote share ties; fortunately
for this analysis, there were no ties.
- Use `dplyr` library and `ifelse` function within `mutate`
- Create the binary LDA MVP variable based on our rule
<!-- -->
mvp_finalist_data = mvp_finalist_data %>%
group_by(Year) %>%
mutate(`LDA MVP` = ifelse(`LDA Prediction` == max(`LDA Prediction`), 1,
ifelse(`LDA Prediction` != max(`LDA Prediction`), 0,0)))
- What did the LDA model do well?
- 30 of 36 MVPs accurately predicted with LDA vote share model
- How do we find where the model "struggled"?
- LDA unsuccessfully predicts MVP
- LDA predicts another player that year with higher vote share as
a better candidate for the MVP
<table>
<caption>LDA Correct MVP Predictions</caption>
<colgroup>
<col width="26%" />
<col width="8%" />
<col width="9%" />
<col width="9%" />
<col width="9%" />
<col width="17%" />
<col width="8%" />
<col width="12%" />
</colgroup>
<thead>
<tr class="header">
<th align="left">Player</th>
<th align="center">Age</th>
<th align="center">Year</th>
<th align="center">Team</th>
<th align="center">Rank</th>
<th align="center">Vote Share</th>
<th align="center">MVP</th>
<th align="center">LDA MVP</th>
</tr>
</thead>
<tbody>
<tr class="odd">
<td align="left">Moses Malone</td>
<td align="center">27</td>
<td align="center">1983</td>
<td align="center">PHI</td>
<td align="center">1</td>
<td align="center">0.96</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="even">
<td align="left">Larry Bird</td>
<td align="center">28</td>
<td align="center">1985</td>
<td align="center">BOS</td>
<td align="center">1</td>
<td align="center">0.978</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="odd">
<td align="left">Larry Bird</td>
<td align="center">29</td>
<td align="center">1986</td>
<td align="center">BOS</td>
<td align="center">1</td>
<td align="center">0.981</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="even">
<td align="left">Magic Johnson</td>
<td align="center">27</td>
<td align="center">1987</td>
<td align="center">LAL</td>
<td align="center">1</td>
<td align="center">0.94</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="odd">
<td align="left">Michael Jordan</td>
<td align="center">24</td>
<td align="center">1988</td>
<td align="center">CHI</td>
<td align="center">1</td>
<td align="center">0.831</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="even">
<td align="left">Magic Johnson</td>
<td align="center">29</td>
<td align="center">1989</td>
<td align="center">LAL</td>
<td align="center">1</td>
<td align="center">0.782</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="odd">
<td align="left">Michael Jordan</td>
<td align="center">27</td>
<td align="center">1991</td>
<td align="center">CHI</td>
<td align="center">1</td>
<td align="center">0.928</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="even">
<td align="left">Michael Jordan</td>
<td align="center">28</td>
<td align="center">1992</td>
<td align="center">CHI</td>
<td align="center">1</td>
<td align="center">0.938</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="odd">
<td align="left">Charles Barkley</td>
<td align="center">29</td>
<td align="center">1993</td>
<td align="center">PHO</td>
<td align="center">1</td>
<td align="center">0.852</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="even">
<td align="left">Hakeem Olajuwon</td>
<td align="center">31</td>
<td align="center">1994</td>
<td align="center">HOU</td>
<td align="center">1</td>
<td align="center">0.88</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="odd">
<td align="left">David Robinson</td>
<td align="center">29</td>
<td align="center">1995</td>
<td align="center">SAS</td>
<td align="center">1</td>
<td align="center">0.858</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="even">
<td align="left">Michael Jordan</td>
<td align="center">32</td>
<td align="center">1996</td>
<td align="center">CHI</td>
<td align="center">1</td>
<td align="center">0.986</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="odd">
<td align="left">Michael Jordan</td>
<td align="center">34</td>
<td align="center">1998</td>
<td align="center">CHI</td>
<td align="center">1</td>
<td align="center">0.934</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="even">
<td align="left">Shaquille O'Neal</td>
<td align="center">27</td>
<td align="center">2000</td>
<td align="center">LAL</td>
<td align="center">1</td>
<td align="center">0.998</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="odd">
<td align="left">Allen Iverson</td>
<td align="center">25</td>
<td align="center">2001</td>
<td align="center">PHI</td>
<td align="center">1</td>
<td align="center">0.904</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="even">
<td align="left">Tim Duncan</td>
<td align="center">25</td>
<td align="center">2002</td>
<td align="center">SAS</td>
<td align="center">1</td>
<td align="center">0.757</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="odd">
<td align="left">Tim Duncan</td>
<td align="center">26</td>
<td align="center">2003</td>
<td align="center">SAS</td>
<td align="center">1</td>
<td align="center">0.808</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="even">
<td align="left">Kevin Garnett</td>
<td align="center">27</td>
<td align="center">2004</td>
<td align="center">MIN</td>
<td align="center">1</td>
<td align="center">0.991</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="odd">
<td align="left">Dirk Nowitzki</td>
<td align="center">28</td>
<td align="center">2007</td>
<td align="center">DAL</td>
<td align="center">1</td>
<td align="center">0.882</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="even">
<td align="left">Kobe Bryant</td>
<td align="center">29</td>
<td align="center">2008</td>
<td align="center">LAL</td>
<td align="center">1</td>
<td align="center">0.873</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="odd">
<td align="left">LeBron James</td>
<td align="center">24</td>
<td align="center">2009</td>
<td align="center">CLE</td>
<td align="center">1</td>
<td align="center">0.969</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="even">
<td align="left">LeBron James</td>
<td align="center">25</td>
<td align="center">2010</td>
<td align="center">CLE</td>
<td align="center">1</td>
<td align="center">0.98</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="odd">
<td align="left">Derrick Rose</td>
<td align="center">22</td>
<td align="center">2011</td>
<td align="center">CHI</td>
<td align="center">1</td>
<td align="center">0.977</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="even">
<td align="left">LeBron James</td>
<td align="center">27</td>
<td align="center">2012</td>
<td align="center">MIA</td>
<td align="center">1</td>
<td align="center">0.888</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="odd">
<td align="left">LeBron James</td>
<td align="center">28</td>
<td align="center">2013</td>
<td align="center">MIA</td>
<td align="center">1</td>
<td align="center">0.998</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="even">
<td align="left">Kevin Durant</td>
<td align="center">25</td>
<td align="center">2014</td>
<td align="center">OKC</td>
<td align="center">1</td>
<td align="center">0.986</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="odd">
<td align="left">Stephen Curry</td>
<td align="center">26</td>
<td align="center">2015</td>
<td align="center">GSW</td>
<td align="center">1</td>
<td align="center">0.922</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="even">
<td align="left">Stephen Curry</td>
<td align="center">27</td>
<td align="center">2016</td>
<td align="center">GSW</td>
<td align="center">1</td>
<td align="center">1</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="odd">
<td align="left">Russell Westbrook</td>
<td align="center">28</td>
<td align="center">2017</td>
<td align="center">OKC</td>
<td align="center">1</td>
<td align="center">0.879</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
<tr class="even">
<td align="left">James Harden</td>
<td align="center">28</td>
<td align="center">2018</td>
<td align="center">HOU</td>
<td align="center">1</td>
<td align="center">0.955</td>
<td align="center">1</td>
<td align="center">1</td>
</tr>
</tbody>
</table>
<br></br>
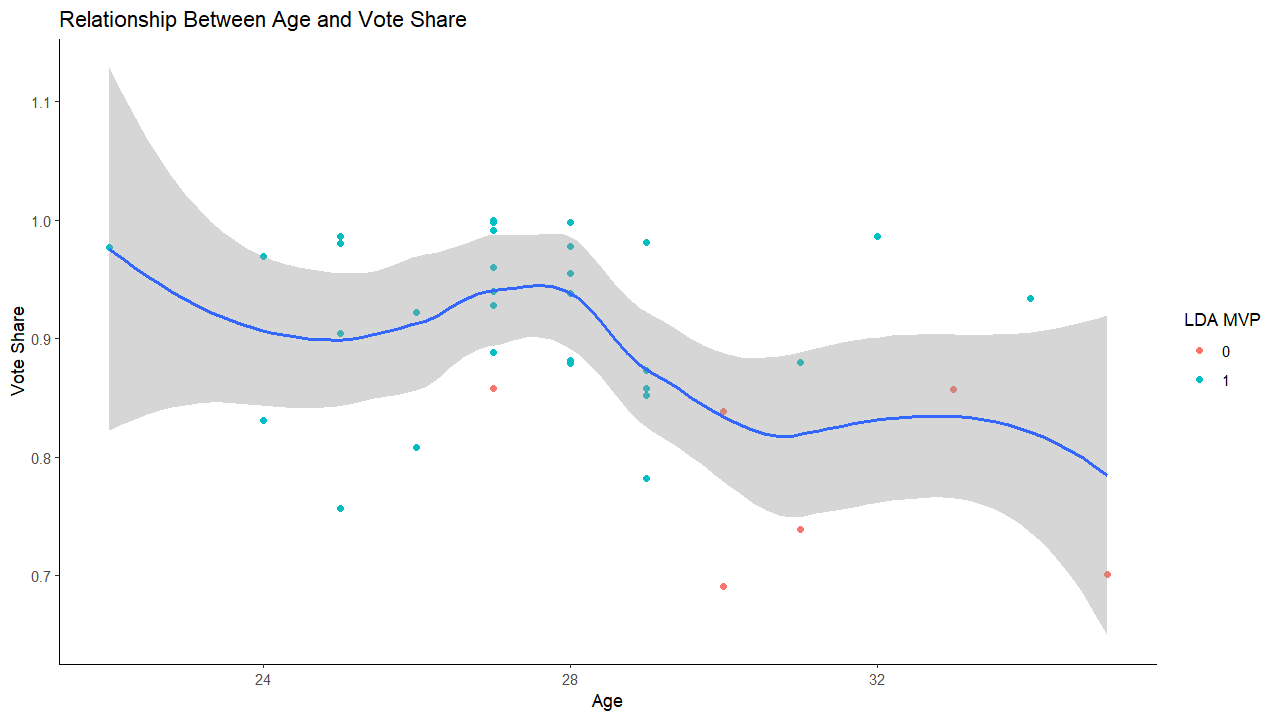
<img src="./age_vote_share_bivariate.png" style="display: block; margin: auto;" />
- Green dots represent MVP winners successfully predicted by the model
- Red dots represent MVP winners the model missed
- MVP winners are clustered between ages 27 and 29
- Older winners average lower vote share
- The model struggled with predicting older MVP winners
### Controversial MVPs
1. Which MVP winner(s) outperformed their predicted vote share?
2. Which MVP winner(s) should have finished second to another finalist
in predicted vote share?
Identify controversial MVPs
- Select MVPs that the LDA model missed
- Create additional column for residual or error
- Absolute value of the difference between actual and predicted
vote share for a MVP finalist
- Residuals help us determine how much a player over- or
under-performed relative to our model
<!-- -->
mvp_finalist_data = mvp_finalist_data %>%
mutate(Residual = abs(`Vote Share`-`LDA Prediction`))
<table>
<caption>Controversial MVPs</caption>
<colgroup>
<col width="18%" />
<col width="6%" />
<col width="7%" />
<col width="7%" />
<col width="14%" />
<col width="19%" />
<col width="12%" />
<col width="12%" />
</colgroup>
<thead>
<tr class="header">
<th align="left">Player</th>
<th align="center">Age</th>
<th align="center">Year</th>
<th align="center">Team</th>
<th align="center">Vote Share</th>
<th align="center">LDA Prediction</th>
<th align="center">Residual</th>
<th align="center">LDA MVP</th>
</tr>
</thead>
<tbody>
<tr class="odd">
<td align="left">Larry Bird</td>
<td align="center">27</td>
<td align="center">1984</td>
<td align="center">BOS</td>
<td align="center">0.858</td>
<td align="center">0.347</td>
<td align="center">0.511</td>
<td align="center">0</td>
</tr>
<tr class="even">
<td align="left">Magic Johnson</td>
<td align="center">30</td>
<td align="center">1990</td>
<td align="center">LAL</td>
<td align="center">0.691</td>
<td align="center">0.518</td>
<td align="center">0.173</td>
<td align="center">0</td>
</tr>
<tr class="odd">
<td align="left">Karl Malone</td>
<td align="center">33</td>
<td align="center">1997</td>
<td align="center">UTA</td>
<td align="center">0.857</td>
<td align="center">0.857</td>
<td align="center">0</td>
<td align="center">0</td>
</tr>
<tr class="even">
<td align="left">Karl Malone</td>
<td align="center">35</td>
<td align="center">1999</td>
<td align="center">UTA</td>
<td align="center">0.701</td>
<td align="center">0.701</td>
<td align="center">0</td>
<td align="center">0</td>
</tr>
<tr class="odd">
<td align="left">Steve Nash</td>
<td align="center">30</td>
<td align="center">2005</td>
<td align="center">PHO</td>
<td align="center">0.839</td>
<td align="center">0.739</td>
<td align="center">0.1</td>
<td align="center">0</td>
</tr>
<tr class="even">
<td align="left">Steve Nash</td>
<td align="center">31</td>
<td align="center">2006</td>
<td align="center">PHO</td>
<td align="center">0.739</td>
<td align="center">0.739</td>
<td align="center">0</td>
<td align="center">0</td>
</tr>
</tbody>
</table>
- Steve Nash (2005, 2006) and Karl Malone (1997, 1999) are repeat
offenders!
- A quick note on Larry in 1984 and Magic in 1990:
- Larry had the highest residual (0.511), overperformance, of any
MVP winner
- Magic Johnson owns the second highest winner residual of 0.173.
- Can't tell a story of basketball without tying Larry and Magic
together.
- The controversial MVP discussion will focus on Malone and Nash
- Whom did the models prefer in 1984, 1990, 1997, 1999, 2005, and
2006?
<table>
<caption>LDA Preferred MVPs</caption>
<colgroup>
<col width="19%" />
<col width="6%" />
<col width="7%" />
<col width="7%" />
<col width="7%" />
<col width="13%" />
<col width="17%" />
<col width="11%" />
<col width="11%" />
</colgroup>
<thead>
<tr class="header">
<th align="left">Player</th>
<th align="center">Age</th>
<th align="center">Year</th>
<th align="center">Team</th>
<th align="center">Rank</th>
<th align="center">Vote Share</th>
<th align="center">LDA Prediction</th>
<th align="center">Residual</th>
<th align="center">LDA MVP</th>
</tr>
</thead>
<tbody>
<tr class="odd">
<td align="left">Bernard King</td>
<td align="center">27</td>
<td align="center">1984</td>
<td align="center">NYK</td>
<td align="center">2</td>
<td align="center">0.491</td>
<td align="center">0.491</td>
<td align="center">0</td>
<td align="center">1</td>
</tr>
<tr class="even">
<td align="left">Charles Barkley</td>
<td align="center">26</td>
<td align="center">1990</td>
<td align="center">PHI</td>
<td align="center">2</td>
<td align="center">0.667</td>
<td align="center">0.667</td>
<td align="center">0</td>
<td align="center">1</td>
</tr>
<tr class="odd">
<td align="left">Michael Jordan</td>
<td align="center">33</td>
<td align="center">1997</td>
<td align="center">CHI</td>
<td align="center">2</td>
<td align="center">0.832</td>
<td align="center">0.934</td>
<td align="center">0.102</td>
<td align="center">1</td>
</tr>
<tr class="even">
<td align="left">Shaquille O'Neal</td>
<td align="center">26</td>
<td align="center">1999</td>
<td align="center">LAL</td>
<td align="center">6</td>
<td align="center">0.075</td>
<td align="center">0.888</td>
<td align="center">0.813</td>
<td align="center">1</td>
</tr>
<tr class="odd">
<td align="left">Shaquille O'Neal</td>
<td align="center">32</td>
<td align="center">2005</td>
<td align="center">MIA</td>
<td align="center">2</td>
<td align="center">0.813</td>
<td align="center">0.813</td>
<td align="center">0</td>
<td align="center">1</td>
</tr>
<tr class="even">
<td align="left">Chauncey Billups</td>
<td align="center">29</td>
<td align="center">2006</td>
<td align="center">DET</td>
<td align="center">5</td>
<td align="center">0.344</td>
<td align="center">0.977</td>
<td align="center">0.633</td>
<td align="center">1</td>
</tr>
</tbody>
</table>
- The model preferred 2<sup>nd</sup> place finishers in 4 of 6
controversial MVP years
- 1984 projects as the only year a potential MVP (Bernard King) would
not have a vote share majority
### The Robbers
- Although Karl Malone and Steve Nash both "stole" 2 MVPs, I'm going
to focus on Steve Nash
- Steve Nash draws more scrutiny because Malone's predicted vote share
in our model doesn't change
- Our model predicts that two players were overlooked in his
winning years
- One such overlooked player was Michael Jordan in 1997
- Jordan would go on to win the 1998 MVP award
- If Jordan had won the 1997 award, his legacy could have spanned
seven MVPs
- Maybe voter fatigue was a factor in denying Jordan his
6<sup>th</sup> MVP (at that time) for Malone's first
- Contrastingly, our model shows that Steve Nash overperformed in one
year
- Nash also should have faced a finalist with better vote share en
route to his second MVP
- Our model suggests that Steve Nash overperformed in 2005 by 0.1
where Malone never overperformed
### The Robbed
- Shaq and Chauncey Billups wildly underperformed in 2 years the model
had them as clear favorites
- Shaq has the most beef as the only player robbed of two potential
MVPs
- Shaq recorded the highest residual prediction value (0.813)
- Shaq was the most underrated MVP finalist ever in his 1999
campaign
- Shaq also loses a MVP in 2005 when our model suggests that Steve
Nash overperformed
- Chauncey in 2006 had the second highest residual of 0.633 and could
be the rightful owner of Steve Nash's second MVP
Review
------
- We compared multiple machine learning regression models to determine
MVP/MVP vote share
- Concluded that Steve Nash and Karl Malone repeatedly robbed
deserving MVP candidates
- Predicted that Larry Bird had the most over-inflated vote share of
any MVP winner
- Voters may have corrected for failing to give MVP awards to Jordan
and Shaq in 1997 and 1999, respectively, by rewarding the players
with the MVP in the subsequent year
Download a .pdf of this [post](downloads/pdf/nba_mvp_comparisons-part_2.pdf)